Tecnología 5G
¿Qué es la tecnología 5G?

Nuevas generaciones de tecnología llegan casi cada 10 años. Se espera que 5G, o la quinta generación de tecnologías móviles, sea 100 veces más rápida y tenga 1000 veces más capacidad que generaciones anteriores, facilitando así una conectividad rápida y confiable, un flujo de datos más amplio y la comunicación máquina a máquina. 5G no está diseñado principalmente para conectar personas, sino más bien aparatos. 2G facilitó el acceso a las llamadas de voz y el texting, 3G impulsó los servicios de videos y de redes sociales, y 4G hizo realidad el streaming digital y las aplicaciones que hacían un gran uso de los datos. 5G apoyará los hogares inteligentes, video en 3D, la nube, servicios médicos remotos, la realidad virtual y aumentada, y la comunicación máquina a máquina para la automatización de la industria. Sin embargo, mientras Estados Unidos, Europa y la región Asia Pacífico hacen la transición de 4G a 5G, muchas otras partes del mundo siguen dependiendo fundamentalmente de las redes 2G y 3G, y hay aún más desigualdades entre la conectividad rural y la urbana. Vea en este video una introducción a la tecnología 5G y tanto el entusiasmo como la cautela que la rodean.
¿Qué queremos decir con “G?”“G” se refiere a generación e indica un umbral para un cambio significativo en la capacidad, arquitectura y tecnología. Estas designaciones son hechas por la industria de telecomunicaciones a través de la autoridad que fija estándares a la que se conoce como 3GPP. 3GPP crea nuevas especificaciones técnicas aproximadamente cada 10 años, de ahí el uso del término “generación”. Un nombre alternativo es la sigla IMT (que quiere decir International Mobile Telecommunications), junto con el año en que el estándar se hizo oficial. Por ejemplo, usted podría ver que 3G también es referido como IMT 2000.
| 1G | Hizo posibles las llamadas telefónicas analógicas; trajo los aparatos móviles (movilidad) |
| 2G | Permitió las llamadas telefónicas y mensajes digitales; hizo posible la adopción masiva y eventualmente posibilitó los datos móviles (2.5G) |
| 3G | Hizo posibles las llamadas telefónicas mensajería y acceso a internet |
| 3.5G | Permitió una internet más fuerte |
| 4G | Permitió una internet más rápida (mejor streaming de video) |
| 5G | “La Internet de las Cosas” Permitirá que los artefactos se conecten entre sí |
| 6G | “La Internet de los Sentidos” Poco se sabe aún |
Este video presenta un panorama simplificado de 1G-4G.

En muchos países en vías de desarrollo hay una brecha entre el estándar celular al que los usuarios se suscriben y el que en realidad usan: muchos se suscriben a 4G pero, como no se desempeña como se ofrece, pueden regresar a 3G. Este cambio o “fallback” (repliegue) no siempre es evidente para el consumidor, y podría ser más difícil de notar al compararse la 5G con redes anteriores.
No es seguro que la tecnología necesariamente funcione como se ha prometido, incluso cuando la infraestructura de 5G esté instalada y los usuarios tengan acceso a través de artefactos capaces: es en efecto probable que no. 5G seguirá dependiendo de tecnologías 3G y 4G, y las compañías telefónicas seguirán operando paralelamente sus redes 3G y 4G.
¿Cómo funciona la tecnología 5G?
Son varios los indicadores claves de rendimiento (KPI) que 5G espera alcanzar. Ella fundamentalmente fortalecerá las redes de celulares usando más frecuencias de radio, conjuntamente con nuevas técnicas para fortalecer y multiplicar los puntos de conexión. Esto quiere decir una conexión más rápida: reducir el tiempo entre un clic en su aparato y el tiempo que le toma ejecutar dicho comando. Esto a su vez permitirá que más aparatos se conecten entre sí a través de la internet de las cosas.
Entendiendo el espectroPara entender 5G es importante entender un poco del espectro electromagnético radial. Este video presenta un panorama de cómo es que los teléfonos celulares emplean dicho espectro.
5G traerá consigo servicios más rápidos y robustos usando más espectro. Para establecer una red de 5G, es necesario asegurar por adelantado el espectro para dicho fin. Los gobiernos y compañías tienen que negociarlo, usualmente subastando “bandas”, a veces por cantidades gigantescas. La asignación del espectro puede ser un proceso político sumamente complicado. Muchos temen que 5G, que requiere un montón del espectro, amenace la así llamada “diversidad de redes”, esto es la idea de que el espectro debiera usarse para diversos fines entre el gobierno, las empresas y la sociedad.
Para mayor información acerca de la asignación del espectro, consúltese Innovations in Spectrum Management una publicación de Internet Society (2019).
5G espera aprovechar nuevas bandas no utilizadas en la cima del espectro radial, a las que se conoce como ondas milimétricas (mmwaves). Éstas se encuentran mucho menos atiborradas que las bandas inferiores, lo que permite efectuar transferencias de datos más rápidas. Pero las ondas milimétricas son complicadas: su rango máximo es de aproximadamente 1.6 km, y los árboles, muros, lluvia y neblina pueden limitar la distancia por la que la señal viaja a apenas 1 km. En consecuencia, 5G requerirá un volumen más alto de torres de celulares, en comparación con las pocas torres enormes requeridas para 4G. 5G necesitará contar con torres cada 100 metros afuera y cada 50 metros adentro, razón por la cual es más idónea para centros urbanos densos (como veremos más adelante con mayor detenimiento). El potencial teórico de las ondas milimétricas es apasionante, pero en realidad la mayoría de compañías de 5G están intentando implementarlo en las partes inferiores del espectro.
La tecnología 5G funciona en una infraestructura de fibra. Podemos entender la fibra como el sistema nervioso de una red móvil, que conecta los centros de datos con las torres de celulares.

Los operadores móviles y los cuerpos internacionales que fijan estándares, entre ellos la Unión Internacional de Telecomunicaciones, creen que la fibra es el mejor material conector debido a su larga vida, alta capacidad, alta confiabilidad y su capacidad para soportar un tráfico muy alto. Pero la inversión inicial es costosa (un estudio de Deloitte de 2017 calculó que la implementación de 5G en los Estados Unidos requeriría de una inversión de al menos $130 billones en fibra) y a menudo prohibitiva en términos del costo para proveedores y operadores, en particular en los países en vías de desarrollo y en áreas rurales. A veces se publicita a 5G como un reemplazo para la fibra; sin embargo, ésta y 5G son tecnologías complementarias.
El gráfico que aparece a continuación a menudo se emplea para explicar las características primarias que conforman la tecnología de 5G (capacidad mejorada, baja latencia y mejor conectividad), así como las posibles aplicaciones de dichas características.

El mercado de proveedores de 5G está muy concentrado, incluso más que el de generaciones anteriores. Un puñado de compañías son capaces de suministrar la tecnología necesaria a los operadores de telecomunicaciones. Huawei (China), Ericsson (Suecia) y Nokia (Finlandia) han liderado el avance para ampliar 5G y usualmente hacen interface con las compañías de telecomunicaciones locales, proporcionando a veces y servicios de mantenimiento.
En 2019, el gobierno de los Estados Unidos aprobó una ley de defensa de autorización del gasto, la NDAA sección 889, que esencialmente prohíbe que las agencias de los EE.UU. utilicen equipos de telecomunicaciones fabricados por proveedores chinos (por ejemplo, Huawei y ZTE). Se impuso esta restricción por temor a que el gobierno chino pudiera usar su infraestructura de telecomunicaciones para espiar (véase más en la sección Riesgos). La
NDAA sección 889 puede aplicarse a cualquier contrato efectuado con el gobierno de los EE.UU., por lo cual es crucial que las organizaciones que vienen considerando asociarse con proveedores chinos tengan en mente los retos legales que tendría tratar tanto con el gobierno chino como el de los EE.UU. en relación con 5G.
Esto, claro está, quiere decir que la variedad de los fabricantes de 5G de golpe se ha hecho mucho más limitada. Las compañías chinas tienen por lejos la mayor participación del mercado de la tecnología 5G. Huawei tiene la mayoría de las patentes registradas, y la presencia lobbista más vigorosa dentro de la Unión Internacional de Telecomunicaciones.
La cancha del 5G es ferozmente política y hay fuertes tensiones entre China y los Estados Unidos. Dado que la tecnología 5G se encuentra estrechamente conectada con la fabricación de los chips, es importante vigilar la “guerra de los chips”. Es probable que los proveedores que dependen de compañías estadounidenses y chinas queden cogidos en medio a medida que la guerra comercial entre ambos países empeora, puesto que las cadenas de suministro y la fabricación de equipos a menudo depende de ambos países. Peter Bloom, fundador de Rhizomatica, señala que se proyecta que el mercado global de chips habrá de crece hasta $22.41 billones para 2026. Bloom advierte: “El impulso a 5G comprende una plétora de grupos de interés, en particular de gobiernos, instituciones financieras y compañías de telecomunicaciones, que debe analizarse mejor a fin de entender dónde se están moviendo las cosas, qué intereses vienen siendo atendidos, y las posibles consecuencias de dichos cambios”.
¿De qué modo es 5G relevante en el espacio cívico y para la democracia?

5G es la primera generación que no prioriza el acceso y la conectividad para los humanos. Ella más bien brinda un nivel de super-conectividad para casos de uso suntuario y entornos específicos; por ejemplo, las experiencias de realidad virtual mejorada y juegos de video masivamente multiusuario. Muchos de los casos publicitados, como la cirugía remota, son teóricos y experimentales, y aún no existen de modo amplio en la sociedad. En efecto, la telecirugía es uno de los ejemplos más citados de los beneficios de 5G, pero sigue siendo una tecnología prototipo. Su implementación a escala requiere abordar muchas cuestiones técnicas y resolver cuestiones legales, además de desarrollar una red global.
El acceso a la educación, el cuidado de la salud y la información son derechos fundamentales, pero los juegos de video de múltiples jugadores, la realidad virtual y los vehículos autónomos —todos los cuales dependen de 5G— no lo son. 5G es un desvío de la infraestructura crucial, necesaria para poner a la gente en línea para que goce de sus derechos fundamentales y permitir así el funcionamiento de la democracia. En realidad, la concentración en 5G desvía la atención de soluciones inmediatas a la mejora del acceso y del cubrir la brecha digital.
El porcentaje de la población global que usa internet viene subiendo, pero una parte significativa del mundo aún no está conectado a ella. Es poco probable que 5G aborde la brecha en el acceso a internet entre las poblaciones rurales y urbanas, o entre las economías desarrolladas y en vías de desarrollo. Lo que se requiere para mejorar el acceso a internet en contextos industriales en desarrollo es más fibra, más puntos de intercambio de internet (IXP), más torres de celulares, más routers de Internet, más espectro inalámbrico y un suministro eléctrico confiable. En un libro blanco de la industria, sólo una de 125 páginas examinó una versión “reducida” de 5G que aborde las necesidades de áreas con un ingreso medio extremadamente bajo por usuario (ARPU). Estas soluciones incluyen el limitar aún más las áreas geográficas del servicio.

Esta presentación efectuada por la corporación estadounidense INTEL en un foro regional de la UIT en 2016, anuncia las aspiraciones usuales de 5G: vehículos autónomos (denominados “transporte inteligente”), realidad virtual (denominada “aprendizaje electrónico”), cirugía remota (llamada “e-salud”), y sensores para apoyar el manejo del agua y la agricultura. De igual modo, casos sumamente específicos y teóricos de uso futuro — vehículos autónomos, automatización industrial hogares, ciudades y logística inteligente— fueron anunciados durante un webinar de 2020 patrocinado por la Kenya ICT Action Network en asociación con Huawei.
En ambas presentaciones el énfasis recayó en la conexión de objetos, demostrando así que 5G está diseñado para las grandes industrias y no para las personas. E incluso si 5G fuese accesible en las áreas rurales remotas, para acceder a ella la gente probablemente tendría que comprar los más costosos planes de datos ilimitados. Este costo se suma al de tener que adquirir teléfonos inteligentes y aparatos compatibles con 5G. Las compañías de telecomunicaciones mismas calculan que sólo el 3% del África subsahariana usará 5G. Se calcula que para 2025, la mayoría de la gente seguirá usando 3G (aproximadamente 60%) y 4G (alrededor del 40%), una tecnología que ha existido ya por 10 años.
Banda ancha de 5G / Acceso inalámbrico fijo (FWA)
Dado que la mayoría de las personas en los países en contextos en vías de desarrollo industrial se conecta a la internet a través de la infraestructura de telefonía celular y la banda ancha móvil, lo más útil para ellas sería la “banda ancha 5G”, a la cual también se denomina Acceso Inalámbrico Fijo 5G (FWA). FWA está diseñado para reemplazar la infraestructura de “última milla” con una red inalámbrica de 5G. En efecto, esta “última milla” —la distancia final al usuario final— es a menudo la más grande barrera al acceso a internet en todo el mundo. Pero dado que la inmensa mayoría de estas redes de 5G habrán de depender de una conexión de fibra, física, la FWA sin fibra no sería de la misma calidad. Estas redes de FWA serán también más costosas de mantener para los operadores que la infraestructura tradicional o “ancha banda fija estándar”.
Este artículo de Ericsson, uno de los principales proveedores de 5G, afirma que FWA será uno de los principales usos de 5G, pero el artículo muestra que los operadores contarán con una amplia capacidad para adaptar sus tarifas, y admite además que muchos mercados seguirán siendo abordados con 3G y 4G.
Mientras que 5G requiere de una enorme inversión en infraestructura física, las nuevas generaciones de acceso celular a Wi-Fi están haciéndose más accesibles y asequibles. Hay también una creciente variedad de soluciones de “redes comunitarias”, entre ellas redes en malla de Wi-Fi, y a veces hasta fibras de propiedad comunal. Para mayor información consúltese: 5G and the Internet of EveryOne: Motivation, Enablers, and Research Agenda, IEEE (2018). Estas son alternativas importantes a 5G a las que se debe considerar en cualquier contexto (desarrollado y en vías de desarrollo, urbano y rural).
“Si estamos hablando de sed y falta de agua, 5G es fundamentalmente un nuevo tipo de cóctel, un nuevo sabor para atraer consumidores sofisticados, siempre y cuando vivas en lugares rentables para el servicio y puedas pagarlo. La renovación de equipos y aparatos de comunicación es una oportunidad de negocio fundamentalmente para los fabricantes, pero sencillamente no es la mejor ‘agua’ para los clientes desconectados, rurales (que no son premium) e incluso es un problema puesto que la inversión de los operadores es empujada primero por la tendencia a satisfacer a los clientes urbanos de alto poder adquisitivo, y no a difundir la conectividad a la inclusión social/universal de los clientes de bajo poder adquisitivo”. – IGF Dynamic Coalition on Community Networks, en comunicación con los autores de este recurso.
Es crucial que no olvidemos las redes de la generación previa. 2G seguirá siendo importante para brindar una amplia cobertura. Ella ya está sumamente presente (alrededor del 95% en los países de ingreso bajo y medio), requiere de menos datos y transporta bien la voz y el tráfico de SMS, lo que significa que es una opción segura y confiable en muchas situaciones. Además, actualizar los sitios ya existentes de 2G a 3G o 4G es menos costoso que construir sitios nuevos.
La tecnología que 5G facilita (la Internet de las cosas , ciudades inteligentes ,hogares inteligentes) alentará la instalación de chips y sensores en un número cada vez más grande de objetos. Los artefactos que 5G propone conectar no son fundamentalmente teléfonos y computadoras, sino sensores, vehículos, equipos industriales, aparatos médicos implantados, drones, cámaras, etc. Vincular dichos aparatos plantea una serie de problemas de seguridad y privacidad, tal como se explora en la sección Riesgos.
Los actores que más se beneficiarán con 5G no son la ciudadanía o los gobiernos democráticos, sino los corporativos. El modelo empresarial que impulsa 5G gira en torno al acceso de la industria a aparatos conectados: en las manufacturas, la industria automotriz, en el transporte y la logística, en la generación de energía y el monitoreo eficiente, etc. 5G impulsará el crecimiento económico de aquellos actores capaces de beneficiarse con ella, en particular los que están comprometidos con la automatización, pero sería apresurado asumir que dichos beneficios se repartirán por toda la sociedad.
La introducción de 5G introducirá masivamente al sector privado dentro del espacio público a través de los carriers y operadores de internet, así como otras terceras partes detrás de los muchos aparatos conectados. Esta toma del espacio público por parte de actores privados (y usualmente actores privados extranjeros) debe ser considerada cuidadosamente a través del lente de la democracia y de los derechos fundamentales. Es cierto que el sector privado ya entró a nuestros espacios públicos (calles, parques, centros comerciales) con las redes celulares anteriores pero el arribo de 5G, que trae consigo más objetos conectados y mayor frecuencia de torres de celulares, incrementará dicha presencia.
Aunque las redes 5G guardan la promesa de una mejor conectividad, hay una creciente preocupación en torno a su mal uso para efectuar prácticas antidemocráticas. Se ha observado a gobiernos de diversas regiones usando la tecnología para obstruir la transparencia y suprimir el disenso, dándose casos del cierre de internet durante las elecciones y la vigilancia de opositores políticos. Por ejemplo, entre 2014 y 2016, los cierres de internet fueron usados en una tercera parte de las elecciones en el África subsahariana.
Estas prácticas a menudo se ven facilitadas por la colaboración con las compañías que brindan herramientas avanzadas de vigilancia, y que permiten el monitoreo de periodistas y activistas sin el debido proceso. El crecimiento sustancial en la transmisión de datos que 5G ofrece elevó la apuesta, permitiendo potencialmente una vigilancia más ubicua y una amenaza más significativa a la privacidad y los derechos de las personas, en particular los de los marginados. Es más, en el momento en que los sistemas electorales dependen más de la tecnología, con iniciativas para poner el voto en línea, el riesgo de los ciberataques que aprovechan las vulnerabilidades de 5G podrían comprometer la integridad de las elecciones democráticas, lo cual hace que la protección contra estas intrusiones sea una prioridad crucial.
Oportunidades
Los beneficios anunciados de 5G usualmente caen dentro de tres áreas, tal como se esboza a continuación. También se explicará una cuarta área de beneficios que si bien se cita menos en la bibliografía, sería la más directamente beneficiosa para la ciudadanía. Debe apuntarse que estos beneficios no estarán disponibles pronto, y que tal vez jamás sean ampliamente disponibles. Muchos seguirán siendo servicios de elite, disponibles solo bajo condiciones precisas y a alto costo. Otros requerirán de estandarización, infraestructura legal y reguladora, y una adopción generalizada antes de que puedan ser una realidad social.
El cuadro que aparece a continuación, que ha sido tomado de un informe de GSMA, muestra los beneficios usualmente enumerados de 5G. Los de la sección blanca podrían alcanzarse con redes anteriores como 4G, y los de la sección púrpura requerirán de 5G. Esto subraya aún más el hecho que muchos de los objetivos de 5G son en realidad posibles sin ella.
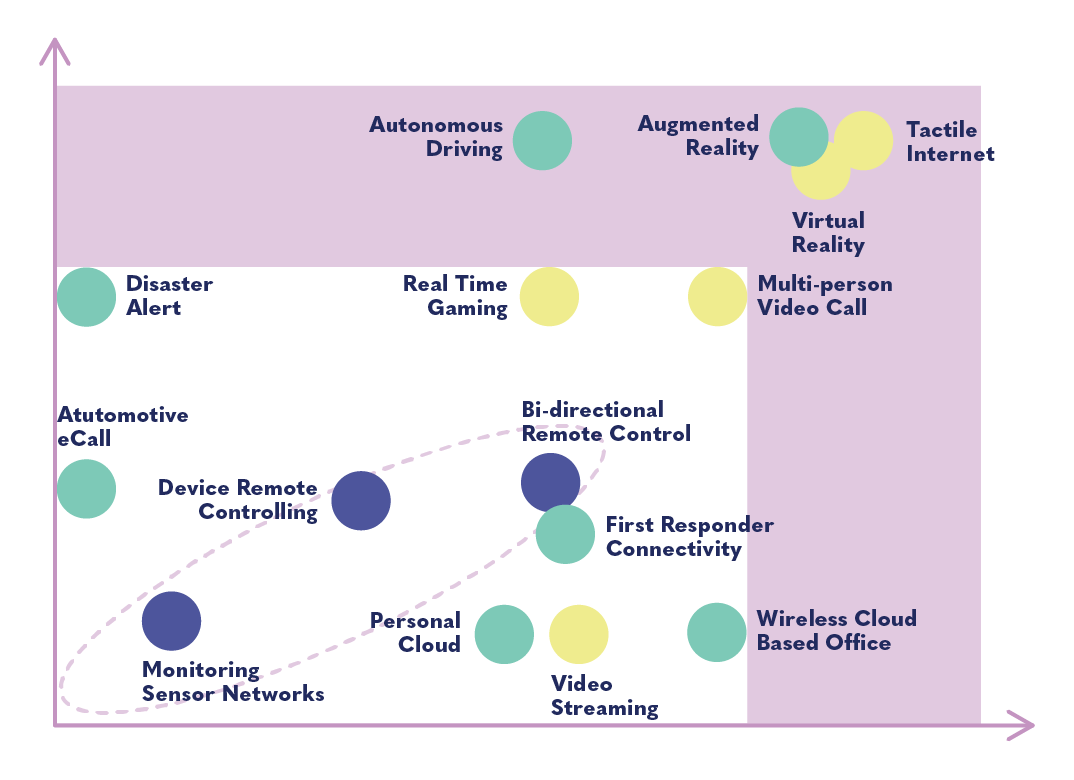
5G tiene muchos usos potenciales en el esparcimiento, y en los juegos en especial. Una baja latencia posibilita los juegos masivos de multijugador, conferencias con video de mayor calidad, descargas más rápidas de videos de alta calidad, etc. La realidad virtual y aumentada son promocionadas como formas de crear experiencias inmersivas de aprendizaje en línea. La capacidad de 5G para conectar aparatos posibilitará el uso de dispositivos médicos vestibles a los que se puede controlar remotamente (aunque no sin riesgos de ciberseguridad). Tal vez el ejemplo más fascinante de la “internet táctil” es la posibilidad de la cirugía a distancia: una operación podría ser efectuada por un robot controlado a distancia por un cirujano en algún lugar al otro lado del mundo. Los sistemas necesarios para esto se encuentran en su infancia y dependen también del desarrollo de otras tecnologías, así como de estándares reguladores y legales, y de un modelo empresarial viable.
El mayor beneficio de 5G será en el sector automotriz. Se espera que su alta velocidad permite que los autos se coordinen de forma segura entre sí y con otra infraestructura. Para que los vehículos autónomos sean seguros deberán poder comunicarse entre ellos y con todo lo que les rodea en milisegundos. La súpervelocidad de 5G es importante para poder alcanzar esto. (Al mismo tiempo, 5G plantea otros problemas de seguridad a los vehículos autónomos.)
La conectividad máquina a máquina o M2M, ya existe en muchos aparatos y servicios, pero 5G facilitaría esto aún más. Esto beneficiará a los jugadores industriales (manufactureros, proveedores de logística, etc.), pero podría discutiblemente beneficiar sobre todo a las personas o ciudades que deseen monitorear su uso de ciertos recursos como la energía o el agua. Los sensores instalados pueden ser usados para recolectar datos los cuales a su vez pueden analizarse para ver su eficiencia y el sistema puede entonces optimizarse. Las aplicaciones típicas de M2M en el hogar inteligente incluyen termóstatos y detectores de humo, electrónica de consumo y el monitoreo del cuidado de la salud. Debe señalarse que muchos de estos dispositivos pueden operar con redes de 4G, 3G y hasta 2G.
Tal vez el beneficio más relevante de 5G en contextos en vías de desarrollo industrial será el potencial del FWA. Éste es menos citado en la literatura del marketing porque no permite del todo los beneficios industriales prometidos. Se le debe pensar como un tipo distinto de “5G” puesto que permite una amplitud de conectividad antes que una fortaleza o intensidad revolucionarias. (Véase la sección Banda ancha de 5G / Acceso inalámbrico fijo section.) Como ya se explicó, el FWA requiere aún de inversiones en infraestructura y no necesariamente será más asequible que las alternativas de banda ancha debido al creciente poder dado a los carriers.
Riesgos
El uso de tecnologías emergentes puede asimismo crear riesgos en los programas de la sociedad civil. Lea a continuación cómo distinguir los posibles peligros asociados con 5G en el trabajo de DRG, así como el modo de mitigar consecuencias involuntarias y voluntarias.
Privacidad personalCon 5G conectando más y más aparatos, el sector privado ingresará aún más dentro del espacio público a través de sensores, cámaras, chips, etc. Muchos de los dispositivos conectados serán cosas que antes jamás esperamos que se conectaran a la internet: lavadoras, inodoros, cunas, etc. Algunos incluso estarán dentro de nuestro cuerpo, como los marcapasos inteligentes. La colocación de aparatos con chips en nuestro hogar y entornos facilitará la recolección de datos acerca de nosotros, así como otras formas de vigilancia.
Un número creciente de actores terceros cuenta con métodos sofisticados de recolectar y analizar datos personales. Algunos dispositivos podrían finalmente recolectar sólo metadatos, pero esto podría reducir seriamente la privacidad. Los metadatos son información relacionada con nuestras comunicaciones que no incluyen su contenido: por ejemplo los números a los que se llamó, las páginas web visitadas, la ubicación geográfica o la hora y fecha en que se hizo una llamada. La corte suprema de la UE ha dictaminado que este tipo de información puede ser considerada igual de sensible que el contenido mismo de la comunicación, debido al conocimiento de nuestra vida privada que los datos pueden ofrecer. 5G permitirá que los operadores de telecomunicaciones y otros actores accedan a los metadatos a los que se puede reunir para tener un conocimiento de nosotros que reducirá nuestra privacidad.
Por último, 5G requiere muchas pequeñas estaciones base de celulares, de modo tal que dichas torres estarán mucho más cerca de los hogares y centros de trabajo de la gente, en semáforos, postes de alumbrado, etc. Esto hará que el monitoreo de la ubicación sea mucho más preciso y hará que la privacidad de la ubicación sea algo casi imposible.
Para la mayoría, 5G será suministrada por compañías extranjeras. En el caso de Huawei y ZTE, el gobierno del país en donde dichas compañías operan (la República Popular China) no defiende las obligaciones de los derechos humanos o los valores democráticos. Por esta razón, a algunos gobiernos les preocupa el potencial para el abuso de los datos por parte del espionaje extranjero. Varios países, entre ellos los Estados Unidos, Australia y el Reino Unido, han tomado medidas para limitar el uso de equipos chinos en sus redes de 5G debido al temor a un posible espionaje. Un informe de 2019 acerca de los riesgos de seguridad de 5G, obra de la Comisión Europea y la Agencia de la Unión Europea para la Ciberseguridad, advierte en contra del uso de un único proveedor en la infraestructura de 5G debido al riesgo de espionaje. El argumento general en contra de un único proveedor (usualmente formulado en contra del proveedor chino Huawei), es que si este suministra la infraestructura central de la red de 5G, entonces su gobierno (China) conseguirá una inmensa capacidad de vigilancia a través de los metadatos, o incluso la “puerta trasera” de una vulnerabilidad. El espionaje gubernamental a través del sector privado y de los equipos de telecomunicaciones son algo común y China no es el único culpable. Pero la masiva capacidad de las redes de 5G y los muchos aparatos conectados que recogen información personal, mejorarán la información en juego así como los riesgos.
Como regla general, cuanto más conectados digitalmente estemos, tanto más vulnerables somos a las ciberamenazas. 5G busca hacer que nosotros y nuestros aparatos estemos ultraconectados. Si un vehículo autónomo en una red inteligente es hackeado o se malogra, esto podría generar un peligro físico inmediato y no solo una filtración de información. 5G centraliza la infraestructura alrededor de un núcleo, lo cual hace que sea particularmente vulnerable. Dada la amplia aplicación de las redes basadas en 5G, esta trae consigo la posibilidad creciente de cierres de internet, lo que pone en peligro gran parte de la red.
La infraestructura de 5G podría simplemente tener deficiencias técnicas. Muchas de estas deficiencias aún no se conocen porque esta tecnología aún sigue en las fases piloto. 5G promociona algunas funciones de seguridad mejoradas, pero los agujeros de seguridad permanecerán porque los aparatos seguirán conectados a las redes más antiguas.
Tal como A4AI lo explica, “La introducción de la tecnología 5G demandará una inversión significativa en infraestructura, lo que incluye nuevas torres capaces de suministrar una mayor capacidad, y centros de datos más grandes que funcionan con energía eficiente”. Estos costos probablemente serán pasados a los consumidores, quienes tendrán que comprar aparatos compatibles y datos suficientes. 5G necesita una inversión masiva en infraestructura, incluso en lugares que ya cuentan con una sólida infraestructura 4G, cables de fibra óptica, buenas conexiones de última milla y un suministro eléctrico confiable. Los cálculos del costo total de la implementación de 5G —lo que incluye las inversiones en tecnología y el espectro— alcanzan incluso los $2.7 trillones USD. Dados los muchos riesgos de seguridad, las incertidumbres reguladoras y la naturaleza en general no probada de la tecnología, 5G resulta no ser una inversión segura ni siquiera en los centros urbanos pudientes. El alto costo de su introducción será un obstáculo para su expansión, y no es probable que los precios caigan lo suficiente como para hacer que sea ampliamente asequible.
Dado que se trata de un producto nuevo tan complejo, hay el riesgo de que se compren equipos de baja calidad. 5G es sumamente dependiente de software y servicios de terceros, lo que multiplica las posibilidades de que haya defectos en partes de los equipos (código mal escrito, mala ingeniería, etc.). El proceso de parchar estos fallos podría ser largo, complicado y costoso. Algunas vulnerabilidades podrían quedar sin ser identificadas por mucho tiempo, pero podrían repentinamente provocar severos problemas de seguridad. La falta de cumplimiento de los estándares de la industria o legales podría provocar problemas similares. En algunos casos los nuevos equipos podrían no tener fallos ni ser defectuosos, sino simplemente ser incompatibles con los equipos ya existentes o con las compras hechas a otros proveedores. Es más, tan solo manejar la red de 4G debidamente tiene costos enormes: protegerla de ciberataques, parchar agujeros y enfrentar fallos, y mantener actualizada la infraestructura material. Para estas tareas es necesario contar con operadores humanos calificados y confiables.
La instalación de nueva infraestructura significa la dependencia de actores del sector privado, usualmente de países extranjeros. La dependencia excesiva de actores privados extranjeros genera múltiples preocupaciones, como ya se dijo, relacionadas con la ciberseguridad, la privacidad, el espionaje, los costos excesivos, la compatibilidad, etc. Dado que sólo un puñado de actores son plenamente capaces de suministrar 5G, se corre también el riesgo de hacerse dependiente de un país extranjero. Y dadas la actual tensión geopolítica entre los EE.UU. y China, los países que intenten instalar la tecnología 5G podrían quedar cogidos en el fuego cruzado de una guerra comercial. Así lo explica Jan-Peter Kleinhans, un experto en seguridad y en 5G de Stiftung Neue Verantwortung (SNV): “El caso de Huawei y 5G forma parte de un desarrollo más amplio en las tecnologías de la información y las comunicaciones (TIC). Estamos pasando de un mundo unipolar con los EE.UU. como líder tecnológico, a otro bipolar en el cual China tiene un papel cada vez más dominante en el desarrollo de las TIC”. La carga financiera de este mundo bipolar será pasada a proveedores y clientes.
“Sin un plan completo de la infraestructura de fibra, 5G no revolucionará el acceso a Internet o la velocidad para los clientes rurales. De modo tal que cada vez que la industria afirme que 5G revolucionará el acceso a la banda ancha rural, están haciendo algo más que promocionándolo demasiado, sencillamente están engañando a la gente”. — Ernesto Falcon, la Electronic Frontier Foundation.
5G no es una inversión lucrativa para los operadores en las áreas más rurales y en contextos en vías de desarrollo, en donde la densidad de los dispositivos potencialmente conectados es más baja. En la industria hay un consenso, apoyado por la UIT misma, en que el despliegue inicial de 5G será en áreas urbanas densas, en particular las áreas pudientes con presencia de la industria. Es probable que las áreas rurales y más pobres, que cuentan con menos infraestructura existente, se quedarán atrás porque no son una buena inversión comercial para el sector privado. En las áreas rurales e incluso en las suburbanas, es probable que las ondas milimétricas y las redes de celulares que requieren de densas torres no sean una solución viable. En consecuencia, 5G no cubrirá la brecha digital de las áreas urbanas y de menores ingresos. La reforzará al ofrecer una súperconectividad a los que ya cuentan con acceso y pueden pagar dispositivos aún más costosos, al mismo tiempo que hace que el costo de la conectividad resulte más alto para otros.
Huawei ha compartido que el sitio típico de 5G tiene un requisito energético de más de 11.5 kilowatts, casi 70% más que aquellos que aplican 2G, 3G y 4G. Algunos calculan que la tecnología 5G usará dos a tres veces más energía que las tecnologías móviles previas. 5G requerirá de más infraestructura, lo que significa un mayor suministro energético y más capacidad de las baterías, todo lo cual tiene consecuencias ambientales. Las cuestiones ambientales más significativas asociadas con su implementación provienen de la fabricación de las muchas partes componentes, junto con la proliferación de los nuevos aparatos que usarán la red 5G. Ésta alentará una mayor demanda y consumo de aparatos digitales, y por ende la creación de más chatarra electrónica, lo cual también habrá de tener serias consecuencias ambientales. Según Peter Bloom, el fundador de Rhizomatica, la mayor parte del daño ambiental provocado por 5G tendrá lugar en el sur global. Esto incluye los daños al ambiente y a las comunidades en donde se extraen los materiales y minerales, así como la polución debida a la chatarra electrónica. En los Estados Unidos, la Oficina Nacional de Administración Oceánica y Atmosférica y la NASA reportaron el año pasado que la decisión de abrir las bandas de alto espectro (el espectro de 24 gigahercios) afectaría durante décadas la capacidad de predecir el clima.
Preguntas
Para entender el potencial que 5G tiene para su entorno laboral o comunidad, hágase estas preguntas para evaluar si es la solución más apropiada, más segura, la más efectiva en términos de los costos y la más centrada en el ser humano:
-
¿La gente ya puede conectarse de modo suficiente a la internet? ¿Se cuenta con la infraestructura necesaria (fibra, puntos de intercambio de internet, electricidad) para conectarse a través de 3G o 4G, o mediante Wi-Fi?
-
¿Se cuenta con las condiciones para aplicar 5G efectivamente? Esto es, ¿hay suficiente backhaul de fibra e infraestructura de 4G (recuerde que 5G aún no es una tecnología standalone)?
-
¿Qué caso(s) de uso específico(s) tiene para 5G que no puedan alcanzarse con una red de una generación anterior?
-
¿Qué otros planes se están haciendo para abordar la brecha digital empleando Wi-Fi y redes en malla, competencia y capacitación digital, etc.?
-
¿Quién se beneficiará con el uso de 5G? ¿Quién podrá acceder a ella? ¿Tienen los aparatos apropiados y suficientes datos? ¿El acceso será asequible?
-
¿Quién está suministrando la infraestructura? ¿Qué tanto se puede confiar en ellos en lo que respecta a la calidad, precio, seguridad, privacidad de datos, y posible espionaje?
-
¿Los beneficios de 5G superan los costos y riesgos (en relación con la seguridad, inversión financiera y posibles consecuencias geopolíticas)?
-
¿Se cuenta con suficientes recursos humanos calificados para mantener la infraestructura de 5G? ¿Cómo se resolverán las fallas y las vulnerabilidades?
Estudios de caso
América Latina y el Caribe5G: el impulsor de la sociedad digital de siguiente generación en América Latina y el Caribe
“Muchos países de todo el mundo tienen prisa por adoptar 5G para asegurar rápidamente los significativos beneficios económicos y sociales que trae consigo. Dadas las enormes oportunidades que las redes de 5G habrán de crear, los países de América Latina y el Caribe (ALC) deben adoptarla activamente. Sin embargo, para desplegar exitosamente las redes de 5G en la región, es importante resolver primero los retos que habrán de enfrentar, entre ellos los altos costos de implementación, el asegurar el espectro, la necesidad de desarrollar instituciones y las cuestiones en torno a la activación. Para que las redes de 5G se establezcan y utilicen con éxito, los gobiernos de ALC deben tomar una serie de medidas, entre ellas mejorar la regulación, establecer instituciones y brindar apoyo financiero relacionado con la inversión en la red de 5G”.
El Reino Unido fue de los primeros mercados en lanzar globalmente 5G en 2019. Como sus operadores han intensificado la inversión en 5G, el mercado ha estado a la par con otros países europeos en términos de su performance, pero sigue detrás de “pioneros de la 5G” como Corea del Sur y China. Por motivos de seguridad, en 2020 el gobierno británico prohibió que los operadores emplearan equipos de 5G suministrados por Huawei, la compañía de telecomunicaciones china, y fijó 2023 como fecha límite para el retiro de sus equipos y servicios de las funciones centrales de la red, y 2027 para su retiro total. El Digital Connectivity Forum advirtió en 2022 que el RU estaba en riesgo de no aprovechar plenamente el potencial de 5G debido a su insuficiente inversión, lo cual afectaría el desarrollo de nuevos servicios tecnológicos como los vehículos autónomos, la logística automatizada y la telemedicina.
Los Estados de las Monarquías del Golfo Pérsico fueron de los primeros en el mundo en lanzar nuevos servicios comerciales de 5G, y han invertido fuertemente en 5G y en tecnologías avanzadas. Los proveedores de servicio local árabes están asociándose con ZTE y Nokia para extender su alcance en los países árabes y asiáticos. En muchos países del golfo los proveedores de 5G y de Internet son de propiedad fundamentalmente estatal, consolidando la influencia gubernamental de este modo sobre los servicios o plataformas apoyados por 5G. Esto podría hacer que solicitar el compartir datos o cerrar la Internet resulte más fácil para los gobiernos. Dubái ya viene aplicando tecnología de reconocimiento facial desarrollada por compañías con lazos con el PCCh para su programa “Policía sin Policías” (Ahmed, R. et al., 13).
Corea del Sur se ha establecido como un temprano líder de mercado para el desarrollo de 5G. Sus redes en Asia serán fundamentales para la difusión del desarrollo de 5G dentro de la región. Actualmente la empresa surcoreana Samsung está presente principalmente en el mercado de los aparatos de 5G. Samsung viene siendo considerado como reemplazo de Huawei en las discusiones del “Club D10”, un grupo proveedor de telecomunicaciones fundado por el RU y que consta de los miembros del G7 más India, Australia y Corea del Sur. Sin embargo, los detalles de su agenda aún están por fijarse. Aunque Corea del Sur y otros intentan expandir su papel en 5G, el desacoplar a Huawei de las TIC y los tradeoffs en el comercio seguro están haciendo que el proceso sea más complicado (Ahmed, R. et al., 14).
¿Qué gobiernos han introducido 5G en África?
“En África los gobiernos son optimistas en que un día podrán emplear 5G para efectuar una agricultura a gran escala con drones, introducir vehículos autónomos a las carreteras, conectarse al metaverso, activar hogares inteligentes y mejorar la ciberseguridad. Algunos analistas predicen que para 2034, 5G sumará otros $2.2 trillones a la economía africana. Pero los primeros en impulsar 5G en África enfrentan fuertes problemas que tal vez retrasen sus metas respectivas. Los retos giraron en torno a la claridad de la regulación del espectro, la viabilidad comercial, los plazos de la implementación y el bajo poder adquisitivo de la ciudadanía con respecto a smartphones habilitados para 5G y una internet costosa”. Para mediados de 2022 Botsuana, Egipto, Etiopía, Gabón, Kenia, Lesoto, Madagascar, Mauricio, Nigeria, Senegal, Seychelles, Sudáfrica, Uganda y Zimbabue estaban probando o habían aplicado 5G, pero muchos de estos países tuvieron demoras en su introducción.
Referencias
A continuación aparecen los trabajos citados en este recurso.
- American Institute of Physics. (2019). NOAA warns 5G spectrum interference presents major threat to weather forecasts.
- Battersby, Stephen. (2017). Spectrum wars: The battle for the airwaves. NewScientist.
- Bleiberg, Joshua & Darrell M. West. (2015). 3 ways to provide Internet access to the developing world. Brookings Institution.
- (2018). Making fixed wireless access a reality. Ericsson Mobility Report.
- Gottfried, Ofer. (2019). Why 4G adoption is stalled in developing countries. The Fast Mode.
- (2019). Financing the Future of 5G.
- Grothaus, Michael. (2019). 5G means you’ll have to say goodbye to your location privacy. Fast Company.
- GSM Association. (2014). Understanding 5G: Perspectives on future technological advancements in mobile.
- GSM Association. (2019). The Mobile Economy: Sub-Saharan Africa.
- GSM Association. (2019). The State of Mobile Internet Connectivity.
- (2019). Who is leading the 5G patent race?
- Isah, Mohammed Engha et al. (2019). Effects of columbite/tantalite (COLTAN) mining activities on water quality in Edege-Mbeki mining district of Nasarawa state, North Central Nigeria. Bulletin of the National Research Centre 43.
- (2018). Setting the Scene for 5G: Opportunities and Challenges.
- Kleinhans, Jan-Peter. (2019). Europe’s 5G challenge and why there is no easy way out. Technode.
- Lavallée, Brian. 5G wireless needs fiber, and lots of it. Ciena.
- Littman, Dan et al. (2017). Communications infrastructure upgrade: The need for deep fiber. Deloitte.
- Low, Cherlynn. (2018). How 5G makes use of millimeter waves. Engadget.
- Maccari, Leonardo et al. (2018). 5G and the Internet of EveryOne: Motivation, Enablers, and Research Agenda. 2018 European Conference on Networks and Communication – IEEE.
- Mundy, Jon. (n.d.). 5G vs fibre – Will 5G replace fibre broadband?
- Newman, Lily Hay. (2019). 5G is more secure than 4G and 3G—Except when it’s not. Wired.
- NGMN Alliance. (2015). 5G White Paper.
- NIS Cooperation Group. (2019). EU coordinated risk assessment of the cybersecurity of 5G networks.
- Privacy International. (2019). Welcome to 5G: Privacy and security in a hyperconnected world (or not?).
- Ahmed, Rumana et al. (2021). 5G and the Future Internet: Implications for Developing Democracies and Human Rights. National Democratic Institute.
- Sarpong, Eleanor. (2019). 5G is here! Can it deliver on affordable access to close the digital divide? Alliance for Affordable Internet.
- Song, Stephen, Rey-Moreno, Carlos & Michael Jensen. (2019). Innovations in Spectrum Management. Internet Society.
- Stevis-Gridneff, Matina. (2020). U. recommends limiting, but not banning, Huawei in 5G rollout. The New York Times.
- UN International Telecommunications Union. (2019). 5G Fifth generation of mobile technologies.
- Zaballos, Antonio Garcia et al. (2020). 5G: The Driver for the Next-Generation Digital Society in Latin America and the Caribbean. Inter-American Development Bank.
Recursos adicionales
- La Association for Progressive Communications tuvo un webinar on 5G and Covid-19.
- Finley, Klint & Joanna Pearlstein. (2020). The WIRED Guide to 5G.
- Rhizomatica: una organización sin fines de lucro con sede en México, que cuenta con recursos y artículos en un blog sobre 5G y temas afines (en inglés y español).
- The Prague Proposals: dadas en Praga después de la Prague 5G Security Conference en mayo de 2019.
Related Technologies & Trends
Tecnologías y tendencias

Los Principios para el Desarrollo Digital
- Comprender el ecosistema existente
- Reutilizar y mejorar
- Utilizar estándares abiertos, datos abiertos, código abierto e innovación abierta
- Abordar la privacidad y seguridad