Inteligencia artificial y aprendizaje automático
¿Qué son la IA y el AA?
La inteligencia artificial (IA) es un campo de las ciencias de la computación dedicado a resolver problemas cognitivos usualmente asociados con la inteligencia humana como el aprendizaje, la resolución de problemas y el reconocimiento de patrones. Dicho de otro modo, IA es un término de múltiple contenido al cual se usa para describir nuevos tipos de software que pueden acercarse a la inteligencia humana. No hay una única definición precisa y universal de IA.
El aprendizaje automático (AA) es un subconjunto de IA. Esencialmente es una de las formas en que las computadoras “aprenden”. El AA es un enfoque de IA basado en algoritmos entrenados para que desarrollen sus propias reglas. Esta es una alternativa a los programas tradicionales de computación, en los cuales las reglas deben ser programadas a mano. El aprendizaje automático extrae patrones de los datos y los coloca en distintos conjuntos. Se ha descrito al AA como “la ciencia de hacer que las computadoras actúen sin haber sido programadas explícitamente”. Dos breves videos nos dan explicaciones simples de IA y AA: ¿Qué es la inteligencia artificial? | Explicación de la IA y ¿Qué es el aprendizaje automático?
Otros subconjuntos de AI son el procesamiento de voz, procesamiento de lenguaje natural (PLN), robótica, cibernética, visión artificial, sistemas expertos, sistemas de planificación y computación evolutiva.
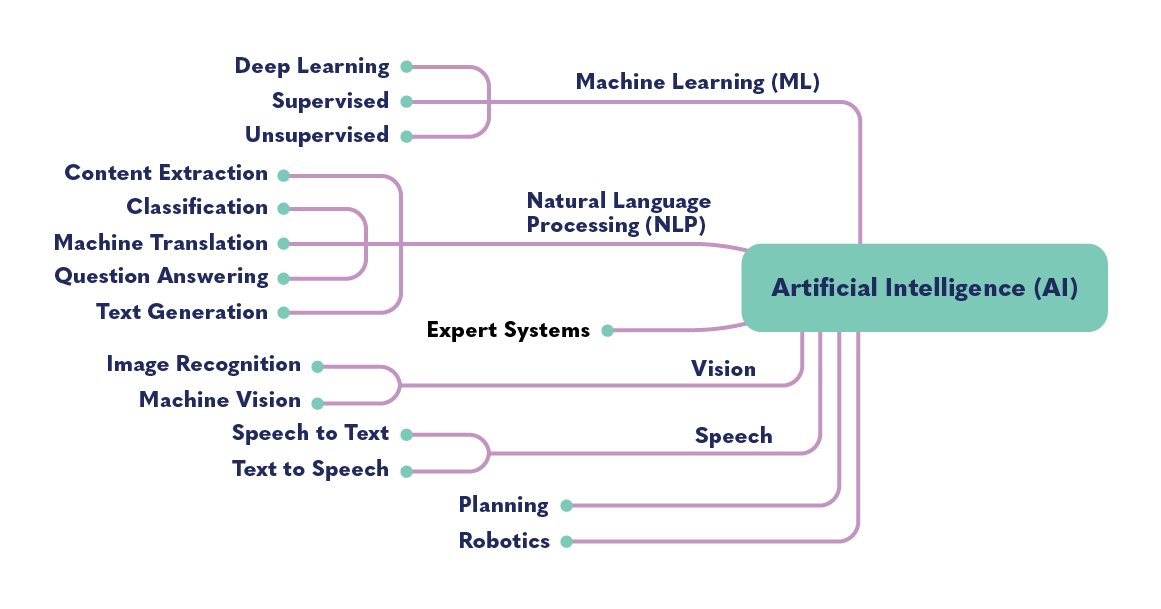
El diagrama anterior muestra los muchos tipos distintos de campos tecnológicos que la IA comprende. Esta última puede referirse a un amplio campo de tecnologías y aplicaciones. El aprendizaje automático es una herramienta empleada para crear sistemas de IA. Cuando nos referimos a esta podemos estar aludiendo a una o varias de estas tecnologías o campos. Las aplicaciones que utilizan IA, como Siri o Alexa, usan múltiples tecnologías. Si, por ejemplo, le decimos a Siri: “Siri, muéstrame la figura de una banana”, usará el procesamiento del lenguaje natural (búsqueda de respuestas) para entender qué se le está preguntado, y luego usará la visión digital (reconocimiento de imágenes) para hallar una banana y mostrársela.
Como ya se indicó, la IA no cuenta con una definición universal. Hay muchos mitos en torno a ella, desde el temor de que controle el mundo esclavizando a los humanos, hasta la esperanza de que algún día se la pueda usar para curar el cáncer. Esta introducción busca brindar una comprensión básica de la inteligencia artificial y el aprendizaje automático, así como esbozar algunos de los beneficios y riesgos que la IA presenta.

Algoritmo: se define a un algoritmo como “una serie finita de instrucciones bien definidas que una computadora puede implementar para resolver un conjunto específico de problemas computacionales”. Los algoritmos son procedimientos nada ambiguos y paso a paso. Un ejemplo simple de un algoritmo sería una receta; otro sería un procedimiento para encontrar al número más grande en un conjunto numérico ordenado aleatoriamente. Un algoritmo puede o bien ser creado por un programador, o sino ser generado automáticamente. En este último caso lo será utilizando datos mediante el AA.
Toma de decisiones algorítmica/Sistema de decisión algorítmica (SDA): los sistemas de decisión algorítmica emplean análisis de datos y estadísticos para tomar decisiones automatizadas, como por ejemplo establecer si una persona es elegible para un beneficio o una pena. Entre los ejemplos de sistemas de decisión algorítmica completamente automatizados tenemos al control electrónico de pasaportes en los aeropuertos, o una decisión automatizada tomada por un banco para otorgar a un cliente un préstamo sin garantía, sobre la base de su historial crediticio y su perfil de datos en el banco. Las herramientas de ayuda a los conductores que controlan el freno, acelerador, conducción, velocidad y dirección de un vehículo son ejemplos de SDA semiautomatizados.
Big Data (macrodatos): hay muchas definiciones del “big data”, pero podemos por lo general pensarlos como conjuntos de datos extremadamente grandes que al ser analizados pueden revelar patrones, tendencias y asociaciones, entre ellos los que se refieren al comportamiento humano. La Big Data se caracteriza por las cinco V: el volumen, velocidad, variedad, veracidad y valor de los datos en cuestión. Este video ofrece una breve introducción a los macrodatos y al concepto de las cinco V.
Class label (etiqueta de clase): una etiqueta de clase se aplica después de que un sistema de aprendizaje automático ha clasificado sus insumos; por ejemplo, establecer si un correo electrónico es spam.
Deep learning (aprendizaje profundo): el aprendizaje profundo es una red neural de tres o más capas que intenta simular el comportamiento del cerebro humano, lo que permite “aprender” de grandes cantidades de datos. Este tipo de aprendizaje impulsa muchas aplicaciones de IA que mejoran la automatización, como los asistentes digitales, los controles remotos de TV activados por la voz, y la detección de fraudes con tarjetas de crédito.
Data mining: (minería de datos) la minería de datos, también conocida como descubrimiento de conocimientos en los datos, es el “proceso de analizar densos volúmenes de datos para encontrar patrones, descubrir tendencias y obtener ideas acerca de cómo podemos emplear los datos”.
La IA generativa[1]: la IA generativa es un tipo de modelo de aprendizaje profundo que puede generar texto, imágenes y otros contenidos de gran cantidad a partir de los datos de entrenamiento. Para mayor información consúltese la sección sobre IA generativa.
Label (etiqueta): una etiqueta es lo que un modelo de aprendizaje automático predice, como el futuro precio del trigo, el tipo de animal mostrado en una imagen, o el significado de un clip de audio.
Large language model (modelo grande de lenguaje): una modelo grande de lenguaje (LLM) es “un tipo de inteligencia artificial que emplea técnicas de aprendizaje profundo y conjuntos de datos masivamente grandes para entender, resumir, generar y predecir contenidos nuevos”. Un LLM es un tipo de IA generativa que ha sido construida específicamente para ayudar a generar contenidos basados en textos.
Model0: un modelo es la representación de lo que un sistema de aprendizaje automático ha aprendido de los datos de entrenamiento.
Red neural: una red neural biológica (BNN) es un sistema en el cerebro que permite sentir estímulos y responder a ellos. Una red neuronal artificial (ANN) es un sistema de computación inspirado por su contraparte biológica en el cerebro humano. En otras palabras, una ANN es “un intento de simular la red de neuronas que conforman un cerebro humano, de modo tal que la computadora pueda aprender y tomar decisiones en forma humana”. Las ANN de gran escala conducen varias aplicaciones de IA.
Perfilamiento: el perfilamiento involucra el procesamiento automatizado de datos para desarrollar perfiles a los cuales se puede usar para tomar decisiones sobre las personas.
Robot: los robots son artefactos programables automatizados. Los que son plenamente autónomos (v.g., los vehículos autónomos) son capaces de operar y tomar decisiones sin el control humano. La IA permite a los robots sentir cambios en su entorno y adaptar sus respuestas y comportamientos en conformidad a ello, para así efectuar tareas complejas sin la intervención humana.
Scoring (puntuación): la puntuación, también llamada predicción, es el proceso mediante el cual un modelo de aprendizaje automático entrenado genera valores a partir de nuevos datos ingresados. Los valores o puntajes que son creados pueden representar predicciones de valores futuros, pero podrían asimismo representar una categoría o resultado probables. Cuando se la usa en relación con personas, la puntuación es una predicción estadística que establece si una persona encaja dentro de una categoría o resultado. Por ejemplo, un puntaje crediticio es un número extraído de un análisis estadístico que representa la solvencia crediticia de una persona.
Supervised learning: en el aprendizaje supervisado, los sistemas de AA son entrenados a partir de datos bien etiquetados. Usando inputs y outputs etiquetados, el modelo puede medir su precisión y aprender con el paso del tiempo.
Aprendizaje no supervisado: el aprendizaje no supervisado emplea algoritmos de aprendizaje automático para así encontrar patrones en conjuntos de datos no etiquetados, sin necesidad de la intervención humana.
Entrenamiento: en el aprendizaje automático, el, entrenamiento es el proceso de establecer los parámetros ideales que un modelo comprende.
¿Cómo operan la inteligencia artificial y el aprendizaje automático?
Inteligencia artificialLa inteligencia artificial es un enfoque transdisciplinario que combina ciencias de la computación, lingüística, psicología, filosofía, biología, neurociencias, estadística, matemática, lógica y economía para “entender, modelar y replicar los procesos de inteligencia y cognitivos”.
Las aplicaciones de IA existen en todo ámbito, industria y en distintos aspectos de la vida cotidiana. Dado que la IA es tan amplia, resulta útil pensarla como estando conformada por tres categorías:
- La IA restringida o inteligencia artificial restringida (ANI) es un sistema experto en una tarea específica, como el reconocimiento de imágenes, jugar Go, o pedirle a Alexa o Siri que respondan una pregunta.
- La IA fuerte o inteligencia artificial general (IAG) es una IA que iguala la inteligencia humana.
- La superinteligencia artificial (ASI) es una IA que supera la capacidad humana.
Las técnicas modernas de IA vienen desarrollándose rápidamente, y sus aplicaciones ya están generalizadas. Sin embargo, estas aplicaciones actualmente solo existen en el campo de la “IA restringida”. La inteligencia artificial general y la superinteligencia artificial aún no han sido alcanzadas, y probablemente no lo serán en los próximos años o décadas.
El aprendizaje automático es una aplicación de la inteligencia artificial. Si bien a menudo encontramos ambos términos usados de modo intercambiable, el primero es un proceso mediante el cual se desarrolla una aplicación de IA. El proceso de aprendizaje automático involucra un algoritmo que efectúa observaciones basadas en los datos, identifica patrones y correlaciones en ellos, y utiliza el patrón o correlación para efectuar predicciones. La mayor parte de la IA actualmente en uso está conducida por el aprendizaje automático.
Así como resulta útil dividir la IA en tres categorías, así también podemos pensar al aprendizaje automático como tres técnicas diferentes: aprendizaje supervisado; aprendizaje no supervisado; y aprendizaje profundo.
El aprendizaje supervisado categoriza eficientemente a los datos según definiciones preexistentes encarnadas en un conjunto de datos que contiene ejemplos de entrenamiento con etiquetas asociadas. Tomemos el ejemplo de un sistema de filtrado de spam, al cual se está entrenando usando correos electrónicos de spam y que no son spam. El “input” en este caso son todos los mensajes que el sistema procesa. Luego de que los humanos han marcado a ciertos mensajes como spam, el sistema los clasifica en otra carpeta. El “output” es la categorización de los mensajes. El sistema encuentra una correlación entre la etiqueta “spam” y las características de los mensajes, como el texto en el “Asunto”, las frases en el cuerpo del mensaje o la dirección de correo o IP del remitente. Usando esta correlación, el sistema intenta predecir la etiqueta correcta (spam/no spam) que aplicar a todos los futuros mensajes que procese.
En este caso, “spam” y “no spam” son denominadas “etiquetas de clase”. La correlación que el sistema halló se llama un “modelo” o “modelo predictivo”. Podemos pensar al modelo como un algoritmo que el sistema de AA genera automáticamente empleando datos. Los mensajes etiquetados a partir de los cuales el sistema aprende son llamados “datos de entrenamiento”. La variable objetivo es la característica que el sistema está buscando o de la cual quiere saber más, en este caso es la condición de spam de un mensaje. A la “respuesta correcta”, por así decirlo, en la categorización del mensaje se la denomina el “resultado deseado” o el “resultado de interés”.
El aprendizaje no supervisado involucra el que las redes neuronales encuentren una relación o patrón sin tener acceso a conjuntos de datos previamente etiquetados de parejas de input-output. Las redes neurales organizan y agrupan los datos por cuenta propia, encontrando patrones recurrentes y detectando desviaciones de dichos patrones. Estos sistemas tienden a ser menos predecibles que los que usan conjuntos de datos etiquetados, y se les aplica más a menudo en entornos que pueden cambiar con cierta frecuencia y no son estructurados o lo están en parte. Algunos ejemplos son:
- Un sistema de reconocimiento óptico de caracteres que puede “leer” textos escritos a mano, aun cuando nunca haya visto dicha escritura antes.
- Los productos recomendados que un usuario ve en las páginas web de ventas al por menor. Estas recomendaciones podrían establecerse asociando al usuario con un gran número de variables tales como su historial de búsqueda, los artículos que ya ha comprado, la calificación que les ha dado, los que guarda en una lista de deseos, la ubicación del usuario, los artefactos que usa, las marcas que prefiere y el precio de sus compras previas.
- La detección de transacciones monetarias fraudulentas sobre la base de la fecha y la ubicación. Por ejemplo, si dos transacciones consecutivas tienen lugar en una misma tarjeta de crédito dentro de un lapso corto y en dos ciudades distintas.
Se usa una combinación de aprendizaje supervisado y no supervisado (lo que se conoce como “aprendizaje semisupervisado”) cuando se cuenta con un conjunto de datos relativamente pequeño y con etiquetas, para entrenar a la red neuronal para que actúe sobre otro conjunto más grande y sin etiquetas. Un ejemplo de aprendizaje semisupervisado es el software que crea deepfakes, o audio, videos o imágenes alterados digitalmente.
El aprendizaje profundo emplea redes neuronales artificiales (ANN) de gran escala llamadas redes neuronales profundas para crear IA que pueda detectar fraudes financieros, efectuar análisis de imágenes médicas, traducir gran cantidad de texto sin intervención humana, y automatizar la moderación de contenido en las páginas de medios sociales. Estas redes neuronales aprenden a efectuar tareas empleando numerosas capas de procesos matemáticos, para así encontrar patrones o relaciones entre distintos puntos de datos en los conjuntos de datos. Un atributo clave del aprendizaje profundo es que estas ANN pueden leer detenidamente, examinar y clasificar cantidades inmensas de datos, lo cual en teoría les permite identificar nuevas soluciones a problemas ya existentes.
La IA generativa[3] es un tipo de modelo de aprendizaje profundo que puede generar textos, imágenes u otros contenidos de gran calidad a partir de los datos de entrenamiento. El lanzamiento de, ChatGPT, el chatbot de OpenAI, a finales de 2022 llamó la atención sobre la IA generativa y desató una carrera entre las compañías para producir versiones alternativas (e idealmente superiores) de esta tecnología. El entusiasmo por los modelos grandes de lenguaje y otras formas de IA generativa también estuvo acompañado por una preocupación por la precisión, el sesgo dentro de dichas herramientas, la privacidad de los datos y cómo se podría usar estas herramientas para propagar la desinformación con mayor eficiencia.
Aunque hay otros tipos de aprendizaje automático, estos tres —el aprendizaje supervisado, el no supervisado y el aprendizaje profundo— representan las técnicas básicas usadas para crear y entrenar sistemas de IA.
La inteligencia artificial es construida por humanos y se la entrena con datos que ellos generan. Inevitablemente hay un riesgo de que los sesgos humanos individuales y sociales sean heredados por los sistemas de IA.
Hay tres tipos de sesgo comunes en los sistemas de computación:
- Los sesgos preexistentes tienen su origen en las instituciones, prácticas y actitudes sociales.
- El sesgo técnico se debe a limitaciones o consideraciones técnicas.
- El sesgo emergente aparece en un contexto de uso.
El sesgo en la inteligencia artificial podría por ejemplo afectar la publicidad política que uno ve en la internet, el contenido movido a la cima de las noticias en las redes sociales, el costo de una prima de seguro, los resultados de la revisión en un proceso de reclutamiento, o la capacidad de pasar a través de los controles de frontera en otro país.
El sesgo en un sistema de computación es un error sistemático y repetible. Dado que el AA lidia con grandes cantidades de datos, hasta una tasa de error pequeña puede agravarse o magnificar, y afectar enormemente a los resultados del sistema. Una decisión que un sistema de AA tome, en particular aquellos que procesan conjuntos de datos gigantescos, a menudo es una predicción estadística. De ahí que su precisión esté relacionada con el tamaño del conjunto de datos. Es probable que los conjuntos de datos de entrenamiento más grandes produzcan decisiones que sean más precisas y reduzcan la posibilidad de error.
El sesgo en los sistemas de IA/AA pueden tener como resultado prácticas discriminatorias, lo que en última instancia llevaría a exacerbar las desigualdades ya existentes o a generar otras nuevas. Para mayor información consúltese este explicador relacionado con el sesgo de la IA y la sección Riesgos de este recurso.
¿De qué modo la IA y el AA son relevantes en el espacio cívico y para la democracia?

La difundida proliferación, rápido despliegue, escala, complejidad e impacto de la IA sobre la sociedad es un tema de gran interés y preocupación para los gobiernos, la sociedad civil, las ONG, organizaciones de derechos humanos, empresas y el público en general. Los sistemas de IA podrían requerir de diversos grados de interacción humana o ninguna en. Cuando se les aplica en el diseño, la operación y el suministro de servicios, la IA/AA brindan el potencial de proveer nuevos servicios y mejorar la velocidad, focalización, precisión, eficiencia, consistencia, calidad o performance de los ya existentes. Pueden brindar nuevas ideas al hacer visibles conexiones, relaciones y patrones antes no descubiertos, y ofrecer nuevas soluciones. Al analizar grandes cantidades de datos, los sistemas de AA ahorran tiempo, dinero y esfuerzos. Algunos ejemplos de la aplicación de la IA/AA en diferentes ámbitos incluyen el uso de algoritmos de IA/AA y datos históricos en la conservación de la vida silvestre para predecir las incursiones de los cazadores furtivos, y para descubrir nuevas especies de virus.

Las capacidades predictivas de la IA y su aplicación así como del AA en la categorización, organización, clustering y búsqueda de información han traído mejoras en muchos campos y ámbitos, entre ellos el cuidado de la salud, el transporte, la gobernanza, educación, energía y en evitar accidentes, así como en la seguridad, la prevención del crimen, la vigilancia policial, la aplicación de la ley, la gestión urbana y el sistema judicial. Por ejemplo, el AA puede usarse para seguir el progreso y la efectividad de los programas de gobierno y filantrópicos. Las administraciones de las ciudades, las de las ciudades inteligentes, inclusive, emplean el AA para analizar datos acumulados a lo largo del tiempo acerca del consumo de energía, la congestión de tráfico, los niveles de contaminación y los desechos, para así monitorear y administrar estas cuestiones e identificar patrones en su generación, consumo y manejo.

La IA también se usa en el monitoreo del clima, el pronóstico del tiempo, la predicción de desastres y peligros, y la planificación del desarrollo de la infraestructura. En el cuidado de la salud, los sistemas de IA ayudan a los profesionales en el diagnóstico médico, la cirugía asistida por robots, una detección más fácil de enfermedades, la predicción de brotes epidémicos, el rastreo de la(s) fuente(s) de la propagación de enfermedades y así sucesivamente. La policía y las agencias de seguridad emplean sistemas de vigilancia basados en la IA/AA, sistemas de reconocimiento facial, drones, y la vigilancia policial predictiva para la seguridad y protección de la ciudadanía. De otro lado, muchas de estas aplicaciones plantean preguntas acerca de la autonomía individual, la privacidad, seguridad, la vigilancia de masas, la desigualdad social y su impacto negativo sobre la democracia (véase la sección Riesgos).

La IA y el AA tienen ambos implicaciones tanto positivas como negativas para las políticas públicas así como para las elecciones, y para la democracia de modo más amplio. Si bien es cierto que los datos pueden usarse para maximizar la efectividad de una campaña mediante mensajes focalizados que ayuden a persuadir a posibles votantes, también pueden emplearse para suministrar propaganda o desinformación a públicos vulnerables. Durante la campaña presidencial de EE.UU de 2016, por ejemplo, Cambridge Analytica utilizó big data y el aprendizaje automático para adaptar los mensajes a los votantes basándose en predicciones a su susceptibilidad a distintos argumentos.
Durante las elecciones del Reino Unido y de Francia en 2017 se usaron, bots políticos para propagar desinformación en las redes sociales y filtrar mensajes electrónicos de campaña privados. Estos bots autónomos están “programados para propagar agresivamente mensajes políticos unilaterales para fabricar así la ilusión del apoyo popular”, o incluso disuadir a ciertas poblaciones de sufragar. Los deepfakes (audios o videos que han sido fabricados o alterados), algo posible gracias a la IA, también contribuyen a propagar la confusión y falsedades acerca de los candidatos políticos y otros actores relevantes. Aunque la inteligencia artificial puede usarse para exacerbar y amplificar la desinformación, también se la puede aplicar en posibles soluciones a este reto. Véase en la sección de Estudios de caso de este recurso, los ejemplos de cómo la industria de verificación de hechos viene aprovechando la inteligencia artificial para identificar y desmentir con mayor efectividad las narrativas falsas y engañosas.
Los ciberatacantes que buscan alterar los procesos electorales emplean el aprendizaje automático para focalizar eficazmente a las víctimas y diseñar estrategias con las cuales vencer las ciberdefensas. Es cierto que estas tácticas pueden usarse para prevenir los ciberataques, pero el nivel de inversión en tecnologías de inteligencia artificial por parte de actores maliciosos supera en muchos casos al de los gobiernos legítimos u otras entidades oficiales. Algunos de estos actores también emplean herramientas de vigilancia digital impulsadas por la IA para seguir y focalizarse en figuras de la oposición, defensores de los derechos humanos y otros críticos identificados.
Como ya se ha examinado en otra parte de este recurso, “el potencial que los sistemas automatizados de toma de decisiones tienen para reforzar sesgos y la discriminación, también tiene un impacto sobre el derecho a la igualdad y la participación en la vida pública”. El sesgo dentro de los sistemas de IA puede dañar a las comunidades históricamente subrepresentadas y exacerbar las divisiones de género existentes, así como los daños en línea que experimentan las mujeres candidatas, políticas, activistas y periodistas.
Las soluciones impulsadas por la IA pueden ayudar a mejorar la transparencia y la legitimidad de las estrategias de campaña, por ejemplo al aprovechar los bots políticos para el bien al ayudar a identificar artículos que contienen desinformación, o brindando una herramienta con la cual recolectar y analizar las preocupaciones de los votantes. La inteligencia artificial puede asimismo usarse para hacer que el trazado de los distritos electorales sea menos partidario (aun cuando en algunos casos también facilita el gerrymandering partidario) y prevenir o detectar fraudes, así como errores administrativos significativos. El aprendizaje automático puede informar la incidencia política prediciendo qué partes de una ley serán aprobadas a partir de evaluaciones algorítmicas del texto de la ley, con cuántos auspiciadores o partidarios cuenta, e incluso en qué parte del año es presentada.
El impacto pleno que el despliegue de sistemas de IA habrá de tener sobre las personas, la sociedad y la democracia no es conocido ni cognoscible, lo cual crea muchos problemas legales, sociales, reguladores, técnicos y éticos. El tema del sesgo nocivo en la inteligencia artificial y su intersección con los derechos humanos y los derechos civiles ha sido motivo de preocupación para gobiernos y activistas. El Reglamento General de Protección de Datos (RGPD) de la Unión Europea cuenta con disposiciones acerca de la toma de decisiones automatizada, el perfilamiento inclusive. En febrero de 2020 la Comisión Europea presentó un libro blanco sobre la IA como precuela a una posible legislación que rigiera su uso en la UE, en tanto que otra de sus organizaciones hizo recomendaciones sobre el impacto de los sistemas algorítmicos en los derechos humanos. Alemania, Francia, Japón e India asimismo han esbozado estrategias de IA para las políticas y leyes. El físico Stephen Hawking una vez dijo, “…el éxito en la creación de la IA podría ser el más grande acontecimiento en la historia de nuestra civilización. Pero también podría ser el último, salvo que aprendamos cómo evitar los riesgos”.
Oportunidades
La inteligencia artificial y el aprendizaje automático pueden tener impactos positivos cuando se los emplea para promover la democracia, los derechos humanos y el buen gobierno. Lea a continuación cómo reflexionar de modo más eficaz y seguro acerca de la inteligencia artificial y el aprendizaje automático en su trabajo.
Detecte y venza los sesgosAunque la inteligencia artificial, como ya vimos, puede reproducir los sesgos humanos, también puede ser usada para combatir los sesgos inconscientes en contextos tales como el reclutamiento laboral. Los algoritmos diseñados de modo responsable pueden sacar sesgos escondidos a la luz, y en algunos casos empujar a la gente hacia resultados menos sesgados, por ejemplo escondiendo el nombre, la edad y otras características en el currículum de los candidatos que activen los sesgos.
Los sistemas de IA pueden usarse para detectar ataques a la infraestructura pública, como un ciberataque o un fraude con tarjetas de crédito. A medida que el fraude en línea se vuelve más desarrollado, las compañías, gobiernos y personas deben poder identificarlo rápidamente, o incluso prevenir que se dé. El aprendizaje automático puede ayudar a identificar patrones ágiles e inusuales que igualan o superan las estrategias tradicionales usadas para evitar la detección.
Cada segundo se sube una cantidad enorme de contenido a la internet y a las redes sociales. Simplemente hay demasiados videos, fotos y publicaciones como para que los humanos puedan revisarlos manualmente. Las herramientas de filtrado, como los algoritmos y las técnicas de aprendizaje automático, son usadas por muchas plataformas de medios sociales para filtrar los contenidos que violan sus condiciones de servicio (como materiales de abuso sexual infantil, violaciones de copyright o spam). La inteligencia artificial está en efecto operando en su cuenta de correo electrónico, filtrando automáticamente los contenidos de marketing no deseados de su buzón principal. El reciente arribo de los deepfakes y otros contenidos generados por computadora requieren de tácticas de identificación igual de avanzadas. Los verificadores de información y otros actores que trabajan para reducir [sic: diffuse] el peligroso y engañoso poder de los deepfakes vienen desarrollando su propia inteligencia artificial para identificar a estos medios de comunicación como falsos.
Los motores de búsqueda operan con sistemas algorítmicos de ranking. Estos motores ciertamente no están libres de serios sesgos y defectos, pero nos permiten ubicar información en las vastas extensiones de la internet. Los motores de búsqueda en la web (como Google y Bing) o dentro de plataformas y páginas web (como las búsquedas dentro de Wikipedia o The New York Times) pueden mejorar sus sistemas algorítmicos de ranking empleando el aprendizaje automático para así favorecer los resultados de alta calidad que pueden ser beneficiosos para la sociedad. Por ejemplo, Google tiene una iniciativa para resaltar reportajes originales, que prioriza el primer caso de una noticia antes que las fuentes que vuelven a publicar la información.
El aprendizaje automático ha hecho posibles unos avances realmente increíbles en la traducción. Por ejemplo, DeepL es una pequeña compañía de traducción automática que ha superado las capacidades traductoras hasta de las más grandes empresas tecnológicas. Otras compañías también han creado algoritmos de traducción que permiten a personas de todo el mundo traducir textos a su lengua preferida, o comunicarse en otras lenguas fuera de aquellas que conocen bien, lo que ha promovido el derecho fundamental del acceso a la información, así como el derecho a la libertad de expresión y a ser escuchado.
Riesgos
El uso de tecnologías emergentes como la IA puede también generar riesgos para la democracia y en los programas de la sociedad civil. Lea a continuación cómo aprender a discernir los posibles peligros asociados con la inteligencia artificial y el aprendizaje automático en el trabajo de DR, así como de qué formas mitigar las consecuencias no intencionales, y también las intencionales.
Discriminación de grupos marginadosHay varias formas en que la IA puede tomar decisiones que podrían generar la discriminación, entre ellas cómo se definen la “variable objetivo” y las “etiquetas de clase en el transcurso del proceso de etiquetado de los datos de entrenamiento; cuando se recogen los datos de entrenamiento; durante la selección de características; y cuando se identifican las proxies. Es asimismo posible configurar intencionalmente un sistema de IA para que discrimine a uno o más grupos. Este video explica de qué modo los sistemas de reconocimiento facial disponibles comercialmente, a los que se entrenó con conjuntos de datos sesgados racialmente, discriminan a las personas de piel oscura, a las mujeres y a las de género diverso.
La precisión de los sistemas de IA se basa en la forma en que el AA procesa el Big Data, lo cual a su vez depende del tamaño del conjunto de datos. Cuanto más grande sea, tanto más probable es que las decisiones del sistema sean más precisas. Sin embargo, es menos probable que las personas negras y la gente de color (PoC), los discapacitados, las minorías, los indígenas, la gente LGBTQ+ y otras minorías más estén representadas en un conjunto de datos debido a la discriminación estructural, el tamaño del grupo o a actitudes externas que impiden su participación plena en la sociedad. El sesgo en los datos de entrenamiento refleja y sistematiza la discriminación existente. Y dado que un sistema de IA es a menudo una caja negra, resulta difícil establecer por qué la IA toma ciertas decisiones acerca de ciertas personas o grupos, o probar concluyentemente que ha tomado una decisión discriminatoria. Resulta por ende difícil evaluar si ciertas personas fueron discriminadas debido a su raza, sexo, estatus marginal u otras características protegidas. Por ejemplo, los sistemas de IA usados en la vigilancia policial predictiva, la prevención del delito, la aplicación de la ley y el sistema de justicia penal son, en cierto sentido, herramientas para la evaluación del riesgo. Empleando datos históricos y algoritmos complejos generan puntajes predictivos que buscan indicar la probabilidad de que se cometa un delito, la ubicación y momento probables, y las personas que posiblemente estén involucradas. Cuando se depende de datos sesgados, o de estructuras de toma de decisiones sesgadas, estos sistemas pueden terminar reforzando estereotipos acerca de los grupos desfavorecidos, marginados o minoritarios.
Un estudio efectuado por la Royal Statistical Society señala que la “…vigilancia predictiva de los delitos relacionados con las drogas tuvo como resultado una vigilancia cada vez más desproporcionada de comunidades históricamente sobre-vigiladas… y en casos extremos, el contacto policial adicional generará oportunidades adicionales de violencia policial en áreas sobre-vigiladas. Cuando el costo de la vigilancia policial es desproporcionado en comparación con el nivel de los delitos, esto equivale a una política discriminatoria”. De igual modo, cuando las aplicaciones móviles para una navegación urbana segura o el software de puntaje crediticio, banca, seguros, cuidado de la salud y la selección de empleados y estudiantes universitarios depende de datos y decisiones sesgados, entonces reforzarán la desigualdad social y los estereotipos negativos y nocivos.
Los riesgos asociados con los sistemas de IA se exacerban cuando éstos toman decisiones o formulan predicciones que involucran a grupos vulnerables tales como los refugiados, o acerca de situaciones de vida o muerte, como en el caso del cuidado médico. Un informe de 2018 preparado por el Citizen Lab de la Universidad de Toronto anota: “Muchos [de los inmigrantes o de quienes buscan asilo] provienen de países asolados por la guerra que buscan protección de la violencia y la persecución. La naturaleza matizada y compleja de muchos refugiados y pedidos de asilo puede ser pasada por alto por estas tecnologías, lo cual provocará serias violaciones de los derechos humanos protegidos internacional y localmente, bajo la forma de sesgos, discriminación, violaciones de la privacidad, cuestiones del debido proceso y de justicia procesal, entre otros. Estos sistemas habrán de tener ramificaciones de vida o muerte para la gente común, muchas de las cuales están huyendo para salvar su vida”. En el caso de los usos médicos y de cuidado de la salud, lo que está en juego es particularmente alto puesto que una decisión errada tomada por el sistema de IA podría potencialmente poner vidas en riesgo, o alterar drásticamente la calidad de vida o el bienestar de las personas que se ven afectadas por ella.
Los hackers maliciosos y las organizaciones criminales pueden emplear los sistemas de AA para identificar vulnerabilidades y poner la mira en la infraestructura pública o en sistemas privados como la internet de las cosas (IdC) y los vehículos autónomos.
Si una entidad maliciosa pone la mira en los sistemas de IA empleados en la infraestructura pública, como las ciudades inteligentes, redes eléctricas inteligentes, instalaciones nucleares, instalaciones para el cuidado de la salud y los sistemas bancarios, entre otros “serán más difíciles de proteger, puesto que estos ataques probablemente se harán más automatizados y complejos, y el riesgo de los fallos en cascada resultará más difícil de predecir. Un adversario inteligente puede o bien intentar descubrir y explotar las debilidades ya existentes en los algoritmos, o sino crear uno al cual posteriormente podrá aprovechar”. El aprovechamiento puede darse, por ejemplo, mediante un ataque de envenenamiento, que interfiere con los datos de entrenamiento cuando se usa el aprendizaje automático. Los atacantes podrían asimismo “usar algoritmos de AA para identificar automáticamente vulnerabilidades y optimizar los ataques estudiando y aprendiendo en tiempo real acerca de los sistemas que tienen en la mira”.
El uso de sistemas de IA sin dispositivos de seguridad y mecanismos de reparación puede plantear muchos riesgos a la privacidad y la protección de datos. Las empresas y gobiernos recolectan inmensas cantidades de datos personales para así entrenar a los algoritmos de los sistemas de IA que brindan servicios o efectúan tareas específicas. Los delincuentes, gobiernos intolerantes y personas con intenciones malignas a menudo ponen la mira en estos datos para así tener un beneficio económico o político. Por ejemplo, de filtrarse los datos de salud captados de las aplicaciones de celulares inteligentes y aparatos vestibles conectados a la internet, podrían ser usados incorrectamente por agencias de crédito, compañías de seguros, brókeres de información, cibercriminales, etc. La cuestión no son solo las filtraciones, sino también los datos que la gente entrega voluntariamente sin control sobre cómo serán usados más adelante. Esto incluye lo que compartimos tanto con las compañías como con las agencias de gobierno. La violación o abuso de los datos no personales, como los datos anonimizados, las simulaciones, los datos sintéticos o las normas generalizadas de procedimientos, podrían también afectar los derechos humano.
Los sistemas de IA usados para la vigilancia y protección, condenas penales, fines legales, etc., se convierten en una nueva vía para el abuso del poder por parte del Estado, para controlar a la ciudadanía y a los disidentes políticos. El temor al perfilamiento, la puntuación, la discriminación y la vigilancia digital omnipresente pueden tener un efecto inhibidor sobre la capacidad o la disposición de la ciudadanía a ejercer sus derechos o a expresarse. Muchas personas modificarán su comportamiento a fin de conseguir los beneficios de contar con un buen puntaje y de evitar las desventajas que se siguen de tener uno malo.
Podemos interpretar la opacidad como ya sea la falta de transparencia, ya de inteligibilidad. Los algoritmos, el código del software, el procesamiento detrás de escena y el proceso mismo de toma de decisiones podrían no ser inteligibles para quienes no son expertos o profesionales especializados. Por ejemplo, en los asuntos legales o judiciales, las decisiones que un sistema de IA toma no viene con explicaciones, a diferencia de las de los jueces, quienes están obligados a justificar su orden legal o juicio.
Los sistemas de automatización, los de IA/AA inclusive, vienen usándose cada vez más para reemplazar el trabajo humano en diversos ámbitos e industrias, eliminando así un gran número de empleos y generando un desempleo estructural (al cual se conoce como desempleo tecnológico). Con la introducción de los sistemas de IA/AA se perderán algunos tipos de trabajos, otros serán transformados, y aparecerán otros nuevos. Es probable que los nuevos trabajos requieran de habilidades específicas o especializadas que sean adaptables a dichos sistemas.
El perfilamiento y la puntuación en la IA despiertan el temor de que las personas sean deshumanizadas y reducidas a un perfil o puntaje. Los sistemas de toma de decisión automatizados podrían afectar el bienestar, la integridad física y la calidad de vida. Esto afecta lo que constituye el consentimiento de una persona (o la falta del mismo), la forma en que se dio, comunicó y entendió el consentimiento, así como el contexto dentro del cual es válido. “[E]l debilitamiento de la base libre de nuestro consentimiento individual —ya sea mediante una distorsión total de la información o incluso con tan solo la ausencia de transparencia— pone en peligro las bases mismas de cómo expresamos nuestros derechos humanos y hacemos que otros rindan cuentas por su privación abierta (o incluso latente)”. – Human Rights in the Era of Automation and Artificial Intelligence
Preguntas
Hágase estas preguntas si está intentando entender las implicaciones que la inteligencia artificial y el aprendizaje automático tendrán en su entorno laboral, o si está considerando usar algunos aspectos de estas tecnologías como parte de su programación DRG:
-
¿La inteligencia artificial o el aprendizaje automático son una herramienta apropiada, necesaria y proporcional para usarla en este proyecto y con esta comunidad?
-
¿Quién está diseñando y supervisando la tecnología? ¿Pueden explicar lo que está sucediendo en las distintas etapas del proceso?
-
¿Qué datos están usándose para diseñar y entrenar la tecnología? ¿De qué modos podrían generar una tecnología sesgada o de funcionamiento defectuoso?
-
¿Qué razones tiene para confiar en las decisiones de la tecnología? ¿Entiende por qué está obteniendo cierto resultado, o podría acaso haber un error en algún lado? ¿Hay algo que no pueda ser explicado?
-
¿Confía en que la tecnología trabajará como se desea cuando la use con su comunidad y en su proyecto, en lugar de en un entorno de laboratorio (o uno teórico)? ¿Qué elementos de su situación podrían causar problemas o cambiar el funcionamiento de la tecnología?
-
¿Quién está analizando e implementando la tecnología de IA/AA? ¿Entienden la tecnología y son conscientes de sus posibles defectos y peligros? ¿Es posible que tomen decisiones sesgadas, ya sea por malinterpretar la tecnología o por alguna otra razón?
-
¿Con qué medidas cuenta para identificar y hacer frente a los sesgos potencialmente dañinos de la tecnología?
-
¿Con qué dispositivos de seguridad reguladores y mecanismos de reparación cuenta, para las personas que sostienen que la tecnología ha sido injusta o que ha abusado de ellos de algún modo?
-
¿Hay alguna forma de que su tecnología de IA/AA pueda perpetuar o incrementar las desigualdades sociales, incluso si los beneficios de su uso superan estos riesgos? ¿Qué hará para minimizar estos problemas y quedar alerta a ellos?
-
¿Está seguro de que la tecnología acata las normas y estándares legales relevantes, el RGPD inclusive?
-
¿Hay alguna forma de que esta tecnología pueda no discriminar a la gente por sí misma, pero que si pueda provocar discriminación o alguna otra violación de derechos, por ejemplo cuando se la aplica en contextos diferentes, o si se comparte con actores no capacitados? ¿Qué podría hacer para prevenir esto?
Estudios de caso
Aprovechando la inteligencia artificial para promover la integridad de la informacióneMonitor+, del Programa de las Naciones Unidas para el Desarrollo, es una plataforma que opera con IA y que ayuda a “escanear en línea las publicaciones de las redes sociales para identificar violaciones electorales, desinformación, discursos de odio, polarización política y pluralismo, así como violencia en línea contra las mujeres”. El análisis de datos facilitado por eMonitor+ permite a las comisiones electorales y las partes interesadas de los medios de comunicación “observar la prevalencia, la naturaleza y el impacto de la violencia en línea. La plataforma depende del aprendizaje automático para seguir y analizar contenidos en los medios digitales y generar representaciones gráficas para la visualización de datos. eMonitor+ ha sido utilizado por Asociación Civil Transparencia y Ama Llulla de Perú, para mapear y analizar la violencia y el discurso de odio digitales en los diálogos políticos, así como por la Comisión Supervisora de las Elecciones durante la elección parlamentaria libanesa de 2022, para monitorear las posibles violaciones electorales, los gasto de campaña y la desinformación. La Alta Comisión Nacional Electoral de Libia también empleó a eMonitor+ para monitorear e identificar en línea la violencia contra las mujeres durante las elecciones.
Antes de la elección presidencial de Nigeria en 2023, Full Fact, la organización verificadora de información del RU, “ofreció su suite de inteligencia artificial —que consta de tres herramientas que trabajan simultáneamente para automatizar los prolongados procesos de verificación de la información— para así ampliar enormemente esta capacidad en Nigeria”. Según Full Fact, estas herramientas no buscan reemplazar a los verificadores humanos, sino más bien ayudarles en el monitoreo y revisión manuales, que toman demasiado tiempo, dándoles así “más tiempo para hacer las cosas en que son mejores: entender lo que importa en el debate público, cuestionar las afirmaciones, revisar datos, hablar con expertos y compartir sus hallazgos”. Las herramientas expandibles, que incluyen funciones de búsqueda, alertas y en vivo, permiten a los verificadores “monitorear páginas web de noticias, redes sociales y transcribir afirmaciones hechas en vivo en la TV o la radio, para así hallar afirmaciones que verificar”.
Monitoreando el desarrollo de los cultivos: Agroscout
“El creciente impacto del cambio climático podría reducir aún más el rendimiento de los cultivos, especialmente en las regiones del mundo de mayor inseguridad alimentaria. Y nuestros sistemas alimentarios son responsables por alrededor del 30% de las emisiones de gases de efecto invernadero. La startup israelí AgroScout imagina un mundo en donde los alimentos se cultivan de modo más sostenible. “Nuestra plataforma usa IA para monitorear el desarrollo de los cultivos en tiempo real, y así planear con mayor precisión las operaciones de procesamiento y manufactura entre regiones, cultivadores y criadores”, dijo Simcha Shore, fundador y CEO de AgroScout. ‘Al utilizar la tecnología de la IA, AgroScout detecta a pestes y enfermedades tempranamente, lo que permite a los granjeros aplicar tratamientos precisos que reducen el uso de agroquímicos hasta en 85%. Esta innovación ayuda a minimizar el daño ambiental provocado por los agroquímicos tradicionales, lo que hace una contribución positiva a las prácticas agrícolas sostenibles’”.
El Machine Learning for Peace Project (Proyecto Aprendizaje Automático para la Paz) busca entender cómo es que el espacio cívico viene cambiando en países de todo el mundo que usan técnicas de aprendizaje automático de última generación. Al aprovechar las últimas innovaciones en el procesamiento de lenguaje natural, el proyecto clasifica “un corpus enorme de noticias digitales en 19 tipos de ‘acontecimientos’ de espacio cívico y 22 tipos de acontecimientos de Resurgent Authoritarian Influence (RAI, influencia autoritaria renaciente), que captan los esfuerzos realizados por regímenes autoritarios para influir en los países en vías de desarrollo”. Entre los “acontecimientos” del espacio cívico que vienen siguiéndose están el activismo, los golpes, las actividades electorales, los cambios legales y las protestas. Los datos de los acontecimientos del espacio cívico se combinan con “datos económicos de alta frecuencia para identificar impulsores claves del espacio cívico y predecir cambios en los meses siguientes”. En última instancia, el proyecto espera servir como una “herramienta útil para los investigadores que buscan datos ricos y de alta frecuencia sobre los regímenes políticos, así como para los decisores de políticas y activistas que luchan para defender la democracia en todo el mundo”.
Seguridad alimentaria: detectando enfermedades en cultivos usando el análisis de imágenes
“Las enfermedades de plantas son una amenaza no solo para la seguridad alimentaria a escala global, sino que pueden además tener consecuencias desastrosas para los pequeños agricultores cuya subsistencia depende de cultivos saludables”. Como primer paso para complementar las soluciones existentes al diagnóstico de enfermedades con un sistema de diagnóstico asistido por celulares, los investigadores usaron un conjunto de datos público de 54,306 imágenes de hojas de plantas enfermas y saludables, para así entrenar una “red neural convolucional profunda” que identifique automáticamente 14 especies de cultivos diferentes y 26 enfermedades singulares (o su ausencia).
Referencias
A continuación encontrará los trabajos citados en este recurso.
- Angwin, Julia et al. (2016). Machine Bias. ProPublica.
- Borgesius, Frederik Zuiderveen. (2018). Discrimination, artificial intelligence, and algorithmic decision-making. Council of Europe.
- Bostrom, Nick. (2014). Superintelligence: Paths, Dangers, Strategies. Oxford University Press.
- Council of Europe. (Adopted on 8 April 2020). Recommendation of the Committee of Ministers to Member states on the human rights impacts of algorithmic systems.
- Dada, Emmanuel et al. (2019). Machine learning for email spam filtering: review, approaches and open research problems. Heliyon 5(6).
- De Winter, Daniëlle, Lammers, Ellen & Mark Noort. (2019). 33 Showcases: Digitalisation and Development. Dutch Ministry of Foreign Affairs.
- Desierto, Diane. (2020). Human Rights in the Era of Automation and Artificial Intelligence. EJIL:Talk! Blog of the European Journal of International Law.
- European Commission. (2020). On Artificial Intelligence – A European Approach to Excellence and Trust. EJIL:Talk! Blog of the European Journal of International Law.
- Casteluccia, Claude & Daniel Le Métayer. (2019). Understanding algorithmic decision-making: Opportunities and challenges. European Parliamentary Research Service.
- Fang, Fei et al. (2016). Deploying PAWS: Field Optimization of the Protection Assistant for Wildlife Security. Proceedings of the Twenty-Eighth AAAI Conference on Innovative Applications (IAAI-16).
- Feldstein, Steven. (2019). How artificial intelligence systems could threaten democracy. The Conversation.
- Frankish, Keith & William M. Ramsey, eds. (2014). The Cambridge Handbook of Artificial Intelligence. Cambridge University Press.
- Friedman, Batya & Helen Nissenbaum. (1996). Bias in Computer Systems. ACM Transactions on Information Systems 14(3).
- Fruci, Chris. (2018). The rise of technological unemployment. The Burn-In.
- German Federal Government. (2018). Key Points for a Federal Government Strategy on Artificial Intelligence.
- Kassner, Michael. (2013). Search engine bias: What search results are telling you (and what they’re not). TechRepublic.
- Knight, Will. (2019). Artificial intelligence is watching us and judging us. Wired.
- Kumar, Arnab et al. (2018). National Strategy for Artificial Intelligence: #AIforAll. NITI Aayog.
- Lum, Kristian & William Isaac. (2016). To predict and serve?. Significance 13(5). Royal Statistical Society.
- Maini, Vishal. (2017). Machine learning for humans. Medium.
- Maxmen, Amy. (2018). Machine learning spots treasure trove of elusive viruses. Nature.
- Miller, Meg. (2017). This app uses AI to track mansplaining in your meetings. Fast Company.
- Mitchell, Tom. (1997). Machine Learning. McGraw Hill.
- Mohanty, Sharada P., Hughes, David P. & Marcel Salathé. (2016). Using Deep Learning for Image-Based Plant Disease Detection. Frontiers in Plant Science.
- Moisejevs, Ilja. (2019). Poisoning attacks on Machine Learning. Towards Data Science.
- Molnar, Petra & Lex Gill. (2018). Bots at the Gate. University of Toronto and Citizen Lab.
- Polli, Frida. (2019). Using AI to Eliminate Bias from Hiring. Harvard Business Review.
- Ridgeway, Andy. (2019). Deepfakes: the fight against this dangerous use of AI. BBC Science Focus Magazine.
- Russell, Stuart J. & Peter Norvig. (1995). Artificial Intelligence: A Modern Approach. Prentice Hall.
- Smith, Floyd. (2019). Case Study: Fraud Detection “On the Swipe” For a Major US Bank. mmSQL Blog.
- Stanford University. (2016). Artificial Intelligence and Life in 2030: Report of the 2015 Study Panel.
- UN Conference on Trade and Development (UNCTAD). (2017). The Role of Science, Technology, and Innovation in Ensuring Food Security by 2030.
- World Commission on the Ethics of Scientific Knowledge and Technology (COMEST). (2017). Report of COMEST on Robotics Ethics. UNESCO and COMEST.
Recursos adicionales
- A brief history of AI: provides a timeline of AI development.
- Access Now. (2018). Human Rights in the Age of Artificial Intelligence.
- AI Myths: website exploring misconceptions around AI.
- Anderson, Michael & Susan Leigh Anderson. (2011). A prima facie duty approach to machine ethics: machine learning of features of ethical dilemmas, prima facie duties, and decision principles through a dialogue with ethicists. In: Anderson, Michael & Susan Leigh Anderson, eds. Machine Ethics. Cambridge University Press, pp. 476-492.
- Awwad, Yazeed et al. (2020). Exploring Fairness in Machine Learning for International Development. USAID, MIT D-Lab and MIT CITE.
- Caulfield, Brian. (2019). Five things you always wanted to know about AI, but weren’t afraid to ask. NVIDIA.
- Commotion Wireless. (2013). Warning Labels Development Part 1 and Part 2.
- Comninos, Alex et al. (2019). Artificial Intelligence for Sustainable Human Development. Global Information Society Watch.
- Council of Europe Human Rights Channel. How to protect ourselves from the dangers of artificial intelligence.
- Molnar, Petra. (2020). The human rights impacts of migration control technologies. European Digital Rights.
- Elish, Madeleine Clare & Danah Boyd. (2017). Situating methods in the magic of big data and artificial intelligence.
- Eubanks, Virginia. (2018). Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor. Macmillan.
- Fairness in Machine Learning and Health: website and resources on the 2019 conference.
- Feldstein, Steven. (2019). The Global Expansion of AI Surveillance. Carnegie Endowment for International Peace.
- Hager, Gregory D. (2017). Artificial Intelligence for Social Good. Association for the Advancement of Artificial Intelligence (AAAI) and Computing Community Consortium.
- Henley, Jon & Robert Booth. (2020). Welfare surveillance system violates human rights, Dutch court rules. The Guardian.
- Johnson, Khari. (2019). How AI can strengthen and defend democracy. VentureBeat.
- Latonero, Mark. (2018). Governing Artificial Intelligence: Upholding Human Rights & Dignity. Data & Society.
- Manyika, James, Silberg, Jake & Brittany Presten. (2019). What do we do about the biases in AI? Harvard Business Review.
- Mitchell, Melanie. (2019). Artificial Intelligence: A Guide for Thinking Humans. Macmillan.
- Müller, Vincent C. (2020). Ethics of Artificial Intelligence and Robotics. Stanford Encyclopedia of Ethics.
- Muro, Mart, Maxim, Robert & Jacob Whiton. (2019). Automation and artificial intelligence: How machines are affecting people and places. Brookings Institution.
- O’Neil, Cathy. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown Publishers.
- Paul, Amy, Jolley, Craig & Aubra Anthony. (2018). Reflecting the Past, Shaping the Future: Making AI Work for International Development. USAID.
- Polyakova, Alina & Chris Meserole. (2019). Exporting Digital Authoritarianism. Brookings Institution.
- Resnick, Brian. (2019). Alexandria Ocasio-Cortez says AI can be biased. She’s right. Vox.
- Sharma, Sid. (2019). What is conversational AI?. NVIDIA.
- Tambe, Milind & Eric Rice, eds. (2018). Artificial Intelligence and Social Work. Cambridge University Press.
- Technology and Human Rights: Series of articles on this relationship from OpenGlobalRights.
- Upturn and Omidyar Network. (2018). Public Scrutiny of Automated Decisions: Early Lessons and Emerging Methods.
Related Technologies & Trends
Tecnologías y tendencias

Los Principios para el Desarrollo Digital
- Diseñar con el usuario
- Comprender el ecosistema existente
- Diseñar para escalar
- Estar guiado por datos
- Utilizar estándares abiertos, datos abiertos, código abierto e innovación abierta
- Abordar la privacidad y seguridad